Deployment Guide
Full platform running
in under an hour.
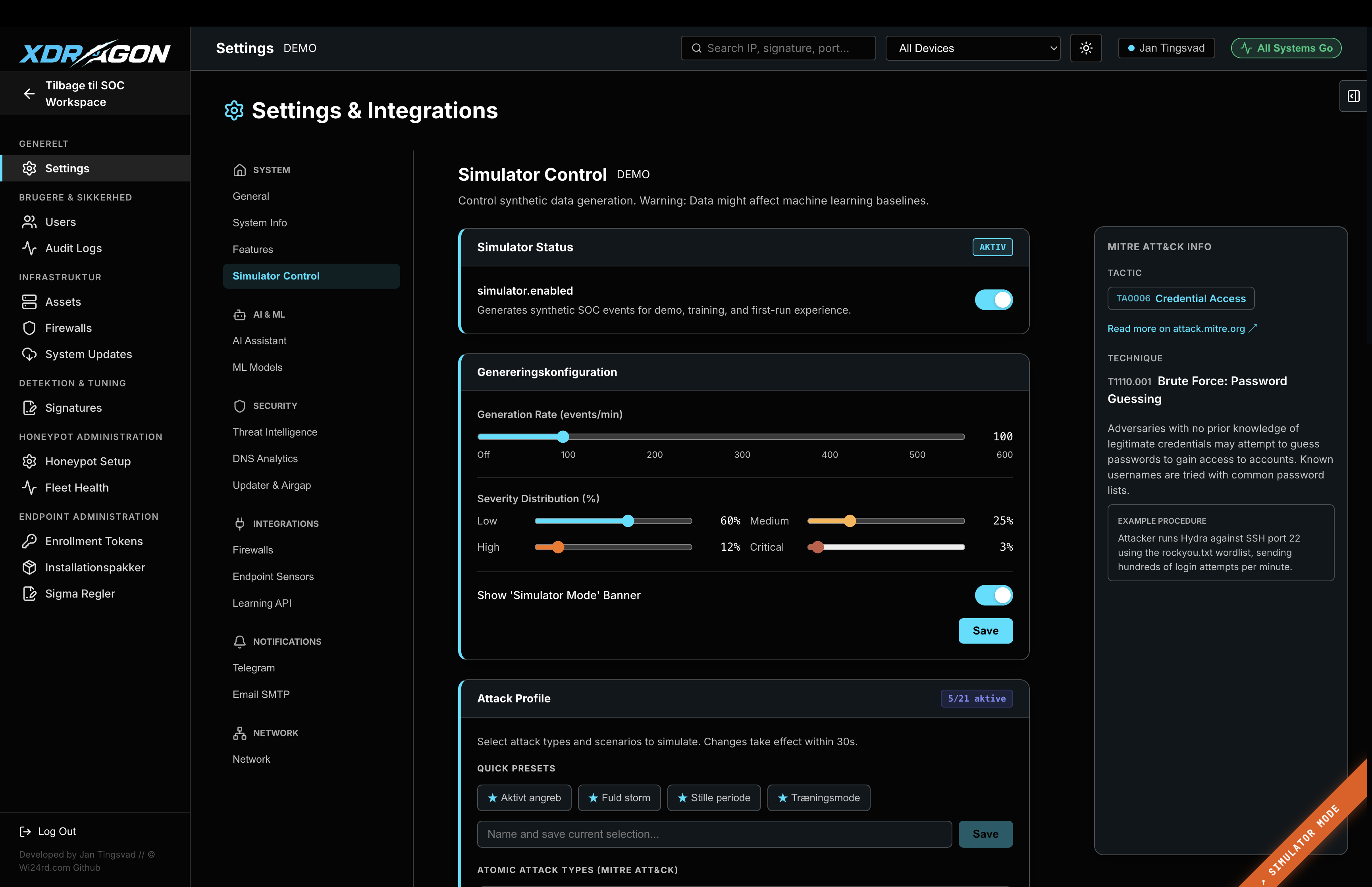
T-SecOps deploys via Docker Compose on standard Linux hardware. Supports Ubuntu 22.04 LTS, Apple Silicon (ARM64), and NVIDIA GPU-accelerated servers. No proprietary appliances. No cloud sign-up.
<60
Minutes to Deploy
Docker
Container-Based
3
Platform Variants
0
Cloud Dependencies